Ensuring correctness in heavy data workloads
While working on a data platform with hundreds of jobs and billions of data points, we faced a simple problem: how do you verify correctness without doubling your infrastructure bill?
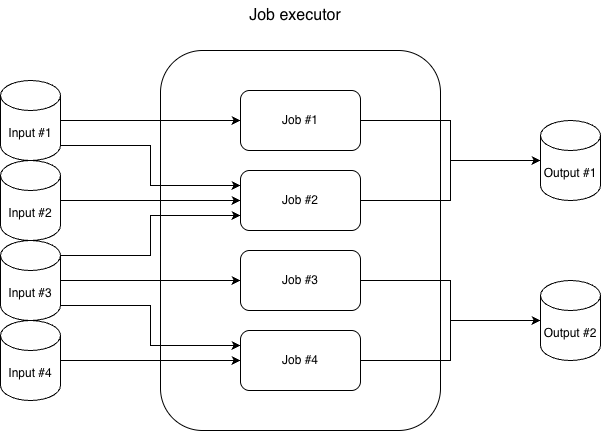
Pipeline architecture
Job config would contain info as:
- Timeframe
- Entities the data is run for
- Input data source
- Output data destination
- Queries to run
- Transformations to run
Input data client was responsible for loading data from its source ( Google BigQuery , Influx, Node RPCs, external apis...) and transforming it to an internal model.
Output data client was responsible for transforming data from our internal data model to the output destination data model.
Job contained actual logic for getting usable metrics, it would filter, group and transform raw data:
- Invoke input data client and download raw data
- Transform raw data into usable metrics
- Invoke output data client and store metrics
Job executor was the entry point in the pipeline. It would take a job config, instantiate data source and destination clients, pass metadata from the job config and run the job.
This modular architecture allowed us to add new metrics to our system easily and maintain a high number of jobs.
Challenges with testing
One of the main sources of our data was Google BigQuery. Standard testing didn't work because of the following:
- Every query incurs costs
- Data in BigQuery can change
- Querying can take 5-10s which is too much for hundreds of jobs
- Mocking BigQuery would only prove that our mocks were correct, not our jobs working with production data
Solution to testing
We used VCR cassettes to record responses from external systems and replay them during tests. This allowed us to run tests against real-world data without repeatedly querying expensive services.
VCR cassettes also solved some of our flaky tests due to BigQuery data updates.
All our VCR records were pushed to our VCS, so CI pipelines would be able to run our whole test suite. Make sure not to push api keys with vcr cassettes.
This approach was not perfect, as the external sources could change, and they did. So we needed to update the vcr cassettes in those cases. It wasn't very frequent though.
All transformed data would end up in our local containers during tests. That's where this package came from.
Challenges with monitoring
The main challenge was incurring costs from logs. Even with low retention, we were uploading so many data points to our log aggregation platform. While it was very practical to debug jobs early and see data points that were in the pipeline, it became to expensive very quickly.
Solution to monitoring
On top of standard logging, we would add data summaries and statistics that could trigger alerts. For example, if we expected a single data point for 1000 entities in a job and we got less than a predefined threshold, we would trigger an alert. This reduced our logging payloads by ~95%.
On top of these data quality alerts, we had standard alerting for job statuses.
It was a nice compromise as our data pipelines were easy to replay due to modularity and internal tooling.
The biggest lesson was that we had to stop treating observability as free.
Summary
We ended up ensuring correctness in two ways:
- Testing jobs against real production data using VCR cassettes
- Monitoring data quality through aggregate statistics rather than raw logs